1.AIGC产业链

AIGC产业链主要分为上游算力硬件层、中游数据/算法软件层和下游行业应用层。硬件层依靠高性能AI芯片、服务器和数据中心为AIGC模型的训练提供算力支持,是承载行业发展的基础设施;数据/算法层软件层主要负责AI数据的采集、清洗、标注及模型的开发与训练,多方厂商入局自然语言处理、计算机视觉、多模态模型等领域;行业应用层目前主要涉及搜索、对话、推荐等场景,未来有望在多个行业呈现井喷式革新。位于算力硬件层的AI芯片是人工智能的底层基石。
2.AI芯片是人工智能的底层基石
2014年李天石博士“DianNao”系列论文让科学界看到,在冯诺依曼架构下也可以实现AI专用芯片。此后Google推出的TPU运算架构的AlphaGo,接连打败李世石和柯洁,看到了专用芯片的商业价值。人工智能经历过三阶段,迎来爆发式增长。
AI人工智能的发展主要依赖两个领域的创新和演进:一是模仿人脑建立起来的数学模型和算法,其次是半导体集成电路AI芯片。AI的发展一直伴随着半导体芯片的演进过程,20世纪90年代,贝尔实验室的杨立昆(YannLeCun)等人一起开发了可以通过训练来识别手写邮政编码的神经网络,但在那个时期,训练一个深度学习卷积神经网络(Convolutional Neural Network,CNN)需要3天的时间,因此无法实际使用,而硬件计算能力的不足,也导致了当时AI科技泡沫的破灭。
AI芯片是AI发展的底层基石。英伟达早在1999年就发明出GPU,但直到2009年才由斯坦福大学发表论文介绍了如何利用现代GPU远超过多核CPU的计算能力(超过70倍),把AI训练时间从几周缩短到了几小时。算力、模型、数据一直是AI发展的三大要素,而AI芯片所代表的算力则是人工智能的底层基石。
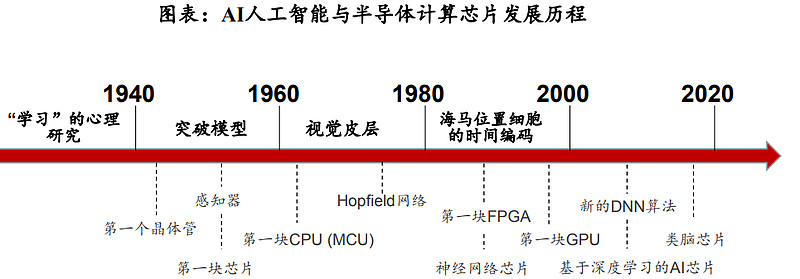
3.训练芯片及推理芯片
根据机器学习算法步骤,AI芯片分为“训练(Training)”芯片和“推理(Inference)”芯片。“训练芯片”主要用于人工智能算法训练,即在云端将一系列经过标记的数据输入算法模型进行计算,不断调整优化算法参数,直至算法识别准确率达到较高水平。“推理芯片”主要用于人工智能算法推理,即将在云端训练好的算法模型进行裁剪优化变“轻”之后,进入“实战”阶段,输入数据直接得出准确的识别结果。
不同用途(训练or推理)、不同应用场景(端-边-云)对AI芯片有着不同的要求。首先,训练芯片追求的是高计算性能(高吞吐率)、低功耗,但是推理芯片主要追求的是低延时(完成推理过程所需要的时间尽可能短)、低功耗。其次,“端-边-云”三个环节对AI芯片的有不同的要求——其中端和边上进行的大部分是AI“推理”,因此用于端和边的AI芯片性能要求和上述推理芯片一致;大部分的训练过程是在云和数据中心进行,训练过程对时延没有什么要求,因此需要保证AI芯片在尽可能保证较高算力的情况下,功耗尽可能低,另外许多推理过程也是在云端进行。

4.终端芯片及云端芯片
根据部署场景,AI 芯片可用于端、边、云三种场景,具体而言:1)终端 AI 芯片追求以低功耗完成推理任务,以实际落地场景需求为导向,在能耗/算力/时延/成本等方面存在差异;2)边缘 AI 芯片介于终端与云端之间,承接低时延/高隐私要求/高网络带宽占用的推理或训练任务;3)云端 AI 芯片以高算力/完成训练任务为目标,包括 CPU/GPU/FPGA/ASIC 等多种类型。

5.GPU、FPGA、ASIC及CPU
从技术架构来看,AI芯片主要分为图形处理器(GPU)、现场可编程门阵列(FPGA)、专用集成电路(ASIC)、中央处理器(CPU)四大类。其中,GPU是较为成熟的通用型人工智能芯片,FPGA和ASIC则是针对人工智能需求特征的半定制和全定制芯片,GPU、FPGA、ASIC作为加速芯片协助CPU进行大规模计算。
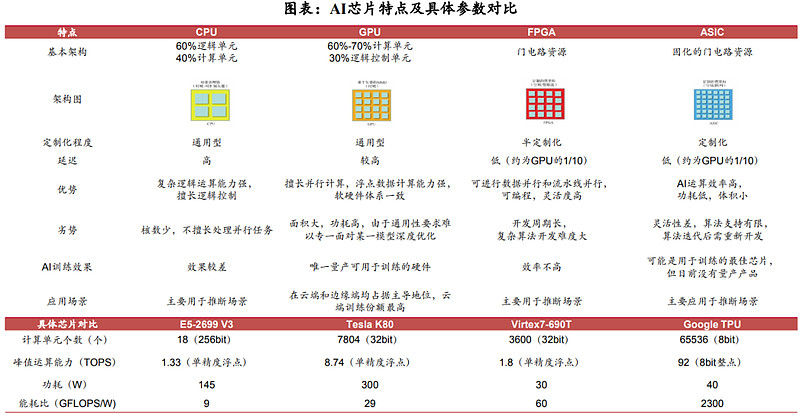
三类芯片用于深度学习时各有优缺点:1)通用性:GPU>FPGA>ASIC,通用性越低,代表其适合支持的算法类型越少。2)性能功耗比:GPU<FPGA<ASIC,性能功耗比越高越好,意味着相同功耗下运算次数越多,训练相同算法所需要的时间越短。
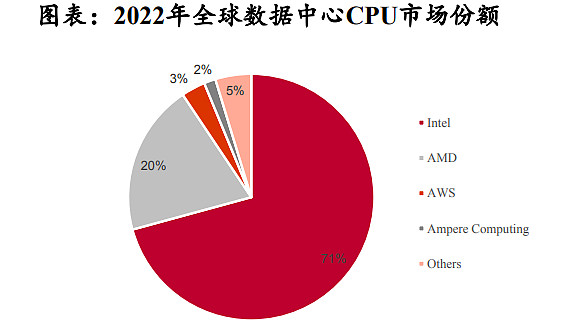
目前AI芯片主要被国际厂商垄断,根据Co unterpoint、IDC数据,Intel和AMD共计占2022年全球数据中心CPU市场收入的92.45%,Nvidia占2021年中国加速卡市场份额的80%以上。
二
AI芯片分类解读
1.CPU:底层核心算力芯片
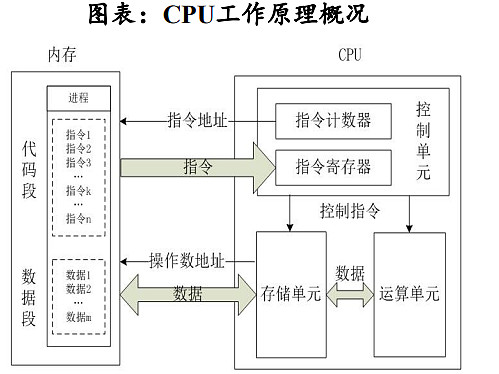
CPU(Central Processing Unit)中央处理器:是计算机的运算和控制核心(Control Unit),是信息处理、程序运行的最终执行单元,主要功能是完成计算机的数据运算以及系统控制功能。
CPU擅长逻辑控制,在深度学习中可用于推理/预测。在深度学习中,模型的训练和推理是两个不同的过程:在训练过程中,模型需要进行大量的矩阵运算,因此通常使用GPU等擅长并行计算的芯片进行处理;在推理过程中,需要对大量的已经训练好的模型进行实时的推理/预测操作,而这种操作通常需要高效的逻辑控制能力和低延迟的响应速度,这正是CPU所擅长的。
2.GPU:AI高性能计算王者
GPU(Graphics Processing Unit)图形处理器:GPU最初是为了满足计算机游戏等图形处理需求而被开发出来的,但凭借高并行计算和大规模数据处理能力,逐渐开始用于通用计算。根据应用场景和处理任务的不同,GPU形成两条分支:
传统GPU:用于图形图像处理,因此内置了一系列专用运算模块,如视频编解码加速引擎、2D加速引擎、图像渲染等;
GPGPU:通用计算图形处理器(general-purpose GPU)。为了更好地支持通用计算,GPGPU减弱了GPU图形显示部分的能力,将其余部分全部投入到通用计算中,同时增加了专用向量、张量、矩阵运算指令,提升了浮点运算的精度和性能,以实现人工智能、专业计算等加速应用。
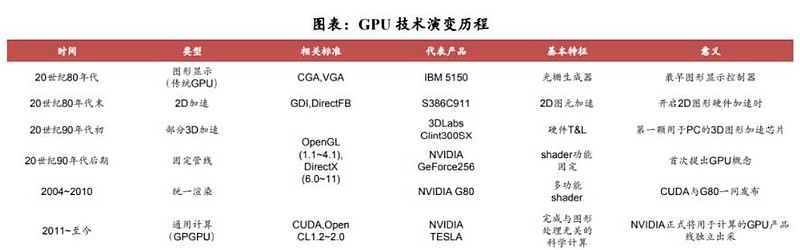
GPU在AI模型构建中具有较高的适配性。GPU的高并行性可以更好地支持AI模型训练和推理过程中大量的矩阵或向量计算,以NVIDIAGPU系列旗舰产品A100为例:根据NVIDIA公布的规格参数,A100的深度学习运算性能可达312Tflops。在AI训练过程中,2048个A100GPU可在一分钟内成规模地处理BERT的训练工作负载;在AI推理过程中,A100可将推理吞吐量提升到高达CPU的249倍。
AI模型与应用的加速发展推动GPU芯片放量增长。根据Verified Market Research数据,2021年全球GPU市场规模为334.7亿美元,预计2030年将达到4773.7亿美元,CAGR(2021-2030)为34.35%。从国内市场来看,2020年中国大陆的独立GPU市场规模为47.39亿元,预计2027年市场规模将达345.57亿美元,CAGR(2021-2027)为32.8%。
3.FPGA:可编程芯片加速替代
FPGA(Field Programmable Gate Array)现场可编程门阵列:FPGA最大的特点在于其现场可编程的特性,无论是CPU、GPU还是ASIC,在芯片制造完成后功能会被固定,用户无法对硬件功能做出更改,而FPGA在制造完成后仍可使用配套软件对芯片进行功能配置,将芯片上空白的模块转化为自身所需的具备特定功能的模块。
(1)可编程性、高并行性、低延迟、低功耗等特点,使得FPGA在AI推断领域潜力巨大
FPGA可以在运行时根据需要进行动态配置和优化功耗,同时拥有流水线并行和数据并行能力,既可以使用数据并行来处理大量数据,也能够凭借流水线并行来提高计算的吞吐量和降低延迟。根据与非网数据,FPGA(Stratix10)在计算密集型任务的吞吐量约为CPU的10倍,延迟与功耗均为GPU的1/10。
云端推断:在面对推断环节的小批量数据处理时,GPU的并行计算优势不明显,FPGA可以凭借流水线并行,达到高并行+低延迟的效果。根据IDC数据,2020年中国云端推理芯片占比已超过50%,预计2025年将达到60.8%,云端推断市场广阔。
边缘推断:受延迟、隐私和带宽限制的驱动,FPGA逐渐被布署于IoT设备当中,以满足低功耗+灵活推理+快速响应的需求。
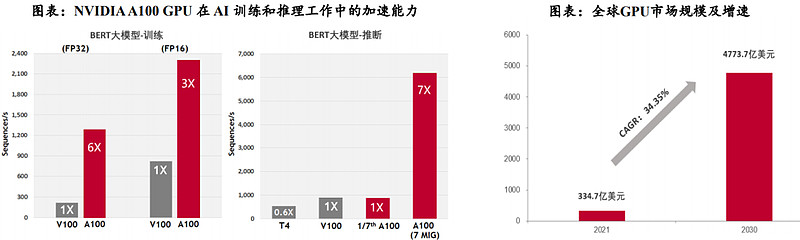
(2)FPGA是AI时代下解决暗硅效应的有效途径
暗硅效应(Dark Silicon)指由于芯片工艺和尺寸的限制,芯片上只有一小部分区域可以同时运行,其余的区域被闲置或关闭,这些闲置或关闭的区域被称为“暗硅”。在AI计算领域,由于摩尔定律的限制和散热问题,先进高效的硬件设计会更容易导致暗硅效应,限制了芯片的计算能力和应用范围。据相关论文,在22nm制程下,暗硅面积将达21%。在8nm制程下,暗硅面积将提升至50%以上。由于暗硅效应,预计到2024年平均只能实现7.9倍的加速比,与每代性能翻倍的目标相比差距将近24倍。
FPGA的可编程性和可重构性使其能够灵活地部署和优化计算任务,从而在一定程度上缓解了暗硅效应的影响。简单来说,FPGA减少暗硅效应的方法有两个方向,一是通过优化电路结构,尽可能减少不活跃区域的数量;二是通过动态重构电路,使得不活跃区域可以被重用。
4.ASIC:云计算专用高端芯片
ASIC(Application Specific Integrated Circuit)专用集成电路:是一种为专门应特定用户要求和特定电子系统的需要而设计、制造的集成电路。ASIC具有较高的能效比和算力水平,但通用性和灵活性较差。
能效方面:由于ASIC是为特定应用程序设计的,其电路可以被高度优化,以最大程度地减少功耗。根据Bob Broderson数据,FPGA的能效比集中在1-10MOPS/mW之间。ASIC的能效比处于专用硬件水平,超过100MOPS/mW,是FPGA的10倍以上。
算力方面:由于ASIC芯片的设计目标非常明确,专门为特定的应用场景进行优化,因此其性能通常比通用芯片更高。根据头豹研究院数据,按照CPU、GPU、FPGA、ASIC顺序,芯片算力水平逐渐增加,其中ASIC算力水平最高,在1万-1000万Mhash/s之间。
随着技术、算法的普及,ASIC将更具备竞争优势。ASIC在研发制作方面一次性成本较高,但量产后平均成本低,具有批量生产的成本优势。目前人工智能属于大爆发时期,大量的算法不断涌出,远没有到算法平稳期,ASIC专用芯片如何做到适应各种算法是当前最大的问题。但随着技术、算法的普及,ASIC将更加具备竞争优势。
ASIC主要应用在推断场景,在终端推断市场份额最大,在云端推断市场增速较快。
5.国产CPU多点开花加速追赶
全球服务器CPU市场目前被Intel和AMD所垄断,国产CPU在性能方面与国际领先水平仍有差距。根据Counterpoint数据,在2022年全球数据中心CPU市场中,Intel以70.77%的市场份额排名第一,AMD以19.84%的份额紧随其后,剩余厂商仅占据9.39%的市场份额,整体上处于垄断局面;目前国内CPU厂商主有海光信息、海思、飞腾、龙芯中科、申威等。通过产品对比发现,目前国产服务器CPU性能已接近Intel中端产品水平,但整体上国内CPU厂商仍在工艺制程、运算速度(主频)、多任务处理(核心与线程数)方面落后于国际先进水平。
6.生态体系逐步完善,国产GPU多领域追赶
全球GPU芯片市场主要由海外厂商占据垄断地位,国产厂商加速布局。全球GPU市场被英伟达、英特尔和AMD三强垄断,英伟达凭借其自身CUDA生态在AI及高性能计算占据绝对主导地位;国内市场中,景嘉微在图形渲染GPU领域持续深耕,另外天数智芯、壁仞科技、登临科技等一批主打AI及高性能计算的GPGPU初创企业正加速涌入。
图形渲染GPU:目前国内厂商在图形渲染GPU方面与国外龙头厂商差距不断缩小。芯动科技的“风华2号”GPU采用5nm工艺制程,与Nvidia最新一代产品RTX40系列持平,实现国产图形渲染GPU破局。景嘉微在工艺制程、核心频率、浮点性能等方面虽落后于Nvidia同代产品,但差距正逐渐缩小。
在GPGPU方面,目前国内厂商与Nvidia在GPGPU上仍存在较大差距。制程方面,目前Nvidia已率先到达4nm,国内厂商多集中在7nm;算力方面,国内厂商大多不支持双精度(FP64)计算,在单精度(FP32)及定点计算(INT8)方面与国外中端产品持平,天数智芯、壁仞科技的AI芯片产品在单精度性能上超过NVIDIAA100;接口方面,壁仞科技与Nvidia率先使用PCle5.0,其余厂商多集中在PCle4.0;生态方面,国内企业多采用OpenCL进行自主生态建设,与NvidiaCUDA的成熟生态相比,差距较为明显。
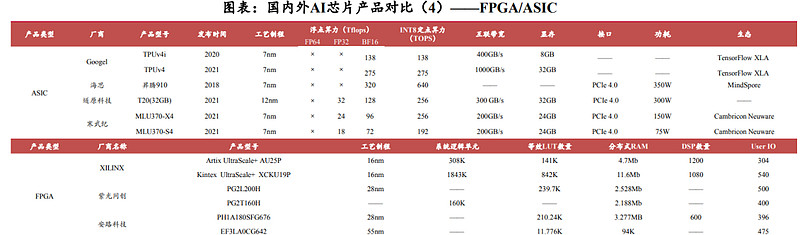
7.FPGA/ASIC国产替代正当时
FPGA全球市场呈现“两大两小”格局,Altera与Xilinx市占率共计超80%,Lattice和Microsemi市占率共计超10%;整体来看,安路科技、紫光同创等厂商处于国际中端水平,仍需进一步突破。工艺制程方面,当前国产厂商先进制程集中在28nm,落后于国际16nm水平;在等效LUT数量上,国产厂商旗舰产品处于200K水平,仅为XILINX高端产品的25%左右。
ASIC不同于CPU、GPU、FPGA,目前全球ASIC市场并未形成明显的头部厂商,国产厂商快速发展;通过产品对比发现,目前国产厂商集中采用7nm工艺制程,与国外ASIC厂商相同;算力方面,海思的昇腾910在BF16浮点算力和INT8定点算力方面超越Googel最新一代产品TPUv4,遂原科技和寒武纪的产品在整体性能上也与Googel比肩。未来国产厂商有望在ASIC领域继续保持技术优势,突破国外厂商在AI芯片的垄断格局。
三
我国AI芯片现状
1.算力精度门槛下,ASIC和GPGPU是最适合大模型的架构
大模型云端训练多数情况下都在FP32计算精度上,推理端则以FP16和混合精度为主。算力越强,模型效率越高。FPGA和GPU对比,虽然FPGA吞吐率、性能功耗比优于GPU,但是FPGA存在两个天然缺陷,FPGA只适合做定点运算,不适合做浮点运算,如果用来做浮点运算耗费逻辑很大,而且有些FPGA不能直接对浮点数进行操作的,只能采用定点数进行数值运算。其二,FPGA可以理解成某种“芯片半成品”,需要开发人员做大量二次开发设计芯片,因此开发使用门槛较高。ASIC和GPU则能够满足大模型的入门门槛。
国内视角下,华为、百度昆仑芯、阿里、寒武纪、海光信息及一众初创企业(燧原、天数、壁仞、沐曦)均推出云端训练和推理芯片。架构选择上,华为、百度、阿里、寒武纪选择ASIC路线。华为、百度、阿里自家业务场景对AI芯片存在天然需求,选择ASIC在量产制造供应链上的难度显著低于GPU。初创企业则押注通用型GPGPU架构,壁仞、沐曦等初创企业多创立于2018年前后,团队一般来自出走英伟达、AMD的技术专家,因此技术路线多选择他们所熟悉的通用型GPU。
2.AI大模型让ASIC和GPU之间的边界愈发模糊,国内GPU初创企业或在竞争中落后
英伟达在过去很长的一段时间内坚持用统一的硬件,即通用型GPU同时支持Deep Learning和图像需求。但高性能计算迭代到H100产品后,其计算卡和图像卡分开,在技术路线上也愈发靠近ASIC。初创企业为了实现通用性,选择了在芯片设计和制造供应链存在较多困难的GPU路线,暂未推出真正具备量产成熟度的产品。
3.国产ASIC厂商中,寒武纪是为数不多能够较为开放支持中游AI算法和模型商
1)华为选择部署端到端的完整生态,例如使用昇腾910必须搭配华为的大模型支持框架Mind Spore、盘古大模型。第三方开源模型无法在华为上运行,若要运营必须依赖华为提供的工具做深度定制和优化,开放程度低。2)阿里在该方面的定位是系统集成商和服务商,运用自身芯片产品搭建加速平台中,对外输出服务。3)百度昆仑芯主要在自身智算集群和服务器上用,以及国内企业、研究所、政府中使用。且由于百度自身AI算法商的商业定位,与其他AI厂商之间存在竞争关系,昆仑芯未必能够在其他AI算法商中铺开。
英伟达A800、H800对国产厂商存在一定的威胁,但在大模型趋势下,英伟达的优势有所弱化。过去,机器学习训练时间的主导因素是计算时间,等待矩阵乘法,通过张量核心和降低浮点精度,这个问题很快被解决。现在大型模型训练/推理中的大部分时间都是在等待数据到达计算资源。内存带宽和容量的限制不断出现在NvidiaA100GPU,如果不进行大量优化,A100往往具有非常低的FLOPS利用率。而800系列降低了数据传输速率,弱化了英伟达高算力的优势。此外,大模型AI芯片更需要片间互联、HBM,英伟达CUDA这种标准化平台的优势同样有所弱化。
寒武纪的优势在于各种深度学习框架,合作经验丰富。寒武纪思元系列产品适配TensorFlow、Pytorch、Caffe深度学习框架。2019年开始适配海康,峰值时刻合作开发团队有70-80人(公司派出20-30人),思元290与商汤在CV层面深度合作,NLP领域在讯飞、百度语音都有出货。
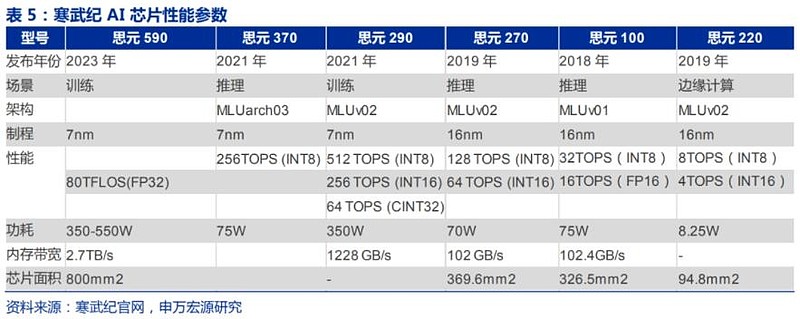
寒武纪思元590将是最早实现商业应用的接近英伟达A100性能的国产AI训练芯片。目前华为昇腾910性能超越英伟达V100,但未达到A100水平,壁仞科技7nm通用GPU芯片BR100称其可与被禁售的英伟达H100一较高下,但尚未量产上市。寒武纪思源590芯片面积800mm^2,和A100一样。内存带宽2.7T,是A1001.8T的1.5倍。HBM2使用海力士,功耗达350W-550W,FP32算力到80TFLops,目前已经客户送样测试阶段,在高性能国产AI芯片中进程最快,最有机会承接国内AI算法商对英伟达A100、H100的需求。
四
AI芯片竞争格局
在不同的应用场景之下,已经形成了不同的AI芯片竞争格局。
1.云和数据中心AI芯片市场
在云和数据中心AI芯片市场,“训练”和“推理”两个环节都是英伟达GPU一家独大,几乎占据90%以上份额,包括AWS、微软Azure、谷歌云、阿里云、华为云、腾讯云在内的大部分公有云厂商上线的AI加速计算公有云服务绝大部分都是基于英伟达Tesla系列GPU。
(1)云端训练
云端训练用的几乎全部是英伟达GPU,公有云厂商中仅谷歌云一家除了提供以英伟达GPU为主的云计算加速服务之外,还推出了基于自研AI芯片TPU的深度学习训练服务;
(2)云端推理
云端推理目前出现了基于GPU、FPGA、ASIC三种不同芯片云计算服务,但是市场份额仍然以英伟达GPU为主,其中AWS、阿里云、腾讯云、华为云等公有云厂商均推出了FPGA加速计算云服务,另外AWS推出了基于自研AI芯片Inferentia的ASIC加速计算服务,华为云推出了基于自研AI芯片昇腾310的ASIC加速计算服务。
2.设备端和边缘计算“推理”市场
在设备端和边缘计算“推理”市场,各类型芯片各自为阵,尚无绝对优势地位的芯片厂商出现——手机市场以高通、华为、苹果原主控芯片厂商为主,自动驾驶、安防IPC领域英伟达暂时领先。
(1)手机
高通从骁龙820开始,就已经具备第一代人工智能引擎AIEngine;高通从第三代AIEngine开始引入异构计算CPU、GPU和DSP的异构并行计算;目前高通已经迭代至第四代,骁龙855是第一个搭载第四代AIEngine的SoC。华为麒麟970、980分别引入寒武纪IP(1A/1H),使得手机SoC开始具备AI能力,在2019年6月华为发布麒麟810,华为与寒武纪合作终止,华为采用了自研AI芯片达芬奇架构(华为在2018年推出了达芬奇架构,对标寒武纪智能处理器IP——Cambricon-1A/1H/1M)。苹果2017年发布的A11芯片也具备了AI能力,附带NeuralEngine和开发平台CoreML用于机器学习。
(2)安防IPC
仍然以采用英伟达Jetson系列GPU为主。例如海康采用了英伟达JetsonTX1,大华睿智系列人脸网络摄像机采用的是英伟达TeslaP4GPU。另外国内三大安防厂商也在陆续采用ASIC芯片,例如海康、大华、宇视在前端智能化摄像机中采用Movidious的Myriad系列芯片,大华自研AI芯片用于新款睿智人脸摄像机。
(3)智能驾驶
L3级别以上自动驾驶芯片以英伟达Drive平台为主(包括Xavier和Orin两款SoC);华为将昇腾310用于自动驾驶域控制器MDC上,2020年已经通过车规级认证;英特尔Mobileye的EyeQ4-5被用在L3-5智能驾驶。但是目前整车厂和Tier1实际采用得最多仍然是以英伟达GPU为主。(在低级别的L1-L2辅助驾驶上,采用的是NXP、瑞萨等厂商的MCU芯片,不涉及深度学习。)
(4)智能音箱
目前智能音箱的语音语义识别均在云端完成推理计算,终端上没有AI专用处理单元。

五
AI芯片四大技术路线
由于AIGC、类GPT应用有鲶鱼效应,带来约百倍算力需求。而英伟达等供给解决需求有瓶颈,因此国产AI芯片有逻辑上需求弹性,AI服务器也有空间。根据IDC数据,2021年全球AI服务器市场规模为156亿美元,预计到2025年全球AI服务器市场将达到318亿美元,预计21-25年CAGR仅仅19.5%。AI服务器的增长和规模总额恐怕无法满足类GPT类应用的百倍需求(例如生产地域、供应商产能、工人等限制),因此AI芯片可能会大量爆发,其次是AI服务器。
近期的行业领袖创业潮,会加速这种趋势。2012-2014年AI创业潮,造就2015-2017年AI机会。2022H2-2023新一轮AI大模型创业潮。
目前AI芯片主要玩家应对英伟达塑造的AI生态壁垒,选取了不同的商业策略:1)英伟达AI芯片依然是AI训练和推理最佳选择;2)寒武纪在走英伟达的路线;3)AMD在走部分兼容CUDA的路线;4)谷歌、华为、百度走的是“深度学习框架+AI芯片”自研路线。
1.英伟达:通用芯片GPU
英伟达目前在深度学习训练芯片市场占据绝对垄断地位,凭借的是:
(1)CUDA及cuDNN、TensorRT等一系列专为深度学习打造的软件工具链
CUDA是实现CPU和GPU分工的编程工具;cuDNN针对深度学习训练,将深度学习模型中对各层(Layer)的常见的操作(例如卷积convolution、池化pooling)以方便理解和使用的接口暴露给开发人员,从而使得开发人员可以快速搭建training的库;TensorRT针对推理环节,帮助模型自动减值和优化;由于开发者对于这些工具已经非常熟悉,由于学习成本的存在不会轻易迁移;
(2)深度学习框架和英伟达AI芯片的高度耦合
由于各家AI芯片厂商编程语言无法兼容,而深度学习框架厂商仅支持一家AI芯片就要投入巨大工程量,因此导致其最终只选择市占率最大的1-2家进行深度支持,英伟达在AI训练和推理上实现了软硬件高度耦合而构筑了极高的生态壁垒。
英伟达高性能训练和推理芯片产品主要包括V100、A100、H100以及3月21日GTC2023发布的H100NVL(2张H100通过外部接口以600GB/s的速度连接,每张卡显存为94GB合计为188GB),预计2024年将推出基于下代Blackwell架构的B100产品。
除上文提到的软件及生态壁垒外,英伟达芯片的主要优势在于大片上内存、高显存带宽以及片间互联方案。
2022年9月起,美国禁止峰值性能等于或大于A100阈值的英伟达芯片向中国出口,合法版本A800、H800已在国内应用。由于中国高性能计算市场对英伟达来说是一个不可放弃的巨大市场,英伟达分别于22年11月、23年3月发布A100、H100的“阉割”版本A800、H800,通过降低数据传输速率(显存带宽)至400GB/s、450GB/s避开美国限制,从而合法出口到中国,根据CEO黄仁勋在GTC2023演讲,H800已在国内BAT的云计算业务中应用。
2.寒武纪:复制英伟达成长之路
寒武纪芯片硬件性能相比于英伟达还有追赶空间,上层软件堆栈与英伟达相似,全自研不是兼容路线;不同之处在于寒武纪需要自己对原生深度学习框架进行修改以支持思元芯片,而英伟达有谷歌原厂支持。硬件方面,从一些表观的性能参数对比来看,寒武纪训练芯片思元290和英伟达A100、昇腾910相比性能还有追赶的空间。软件方面,寒武纪是自己对原生的Tensorflow和Pytorch深度学习框架去针对自己的思元芯片去做修改而非像华为一样自研深度学习框架去进行优化,也不像英伟达一样因为芯片市占率高,有Pytorch/Tensorflow原厂去做GPU算子的优化和设备的支持。另外寒武纪相比英伟达的算子库丰富程度以及软件工具链的完善程度还有一定差距,需要时间去追赶。
3.AMD:部分兼容英伟达CUDA
AMD选择了部分兼容英伟达CUDA,借力英伟达生态的路线。AMD在2016年全球超算大会上推出了ROCm,也就是对标英伟达CUDA一样的智能编程语言,ROCm软件堆栈的结构设计与CUDA相似度很高;对标英伟达深度学习库cuDNN,AMD推出了MIOpen;对标英伟达深度学习推理框架TensorRT,AMD推出了Tensile;对标英伟达编译器NVCC,AMD推出了HCC。ROCm中包含的HIPify工具,可以把CUDA代码一键转换成ROCm栈的API,减少用户移植成本。
走兼容英伟达CUDA的路线其难点在于其更新迭代速度永远跟不上CUDA并且很难做到完全兼容。1)迭代永远慢一步:英伟达GPU在微架构和指令集上迭代很快,在上层软件堆栈上很多地方也要做相应的功能更新;但是AMD不可能知道英伟达的产品路线图,软件更新永远会慢英伟达一步(例如AMD有可能刚宣布支持了CUDA11,但是英伟达已经推出CUDA12了)。2)难以完全兼容反而会增加开发者的工作量:像CUDA这样的大型软件本身架构很复杂,AMD需要投入大量人力物力用几年甚至十几年才能追赶上;因为难免存在功能差异,如果兼容做不好反而会影响性能(虽然99%相似了,但是解决剩下来的1%不同之处可能会消耗开发者99%的时间)。

4.谷歌、华为:“深度学习框架+AI芯片”自研
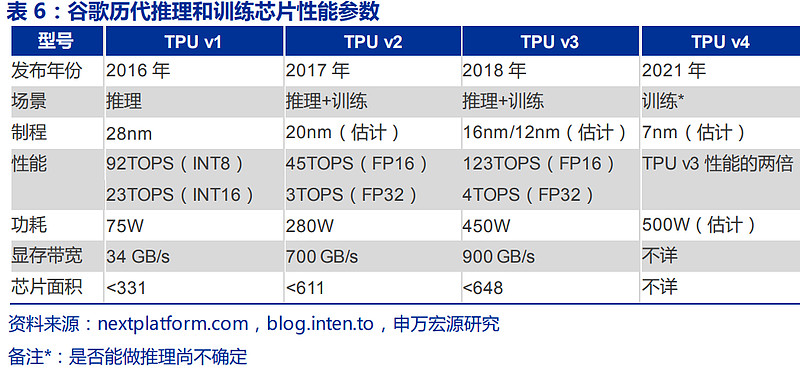
谷歌凭借Tensorflow去做TPU相对而言不存在太多生态壁垒问题,但是仍然无法撼动英伟达,其原因在于TPU本身性能还有进一步提升空间以及过于专用的问题。理论上谷歌凭借Tensorflow在深度学习框架领域实现了垄断地位,是具备绝对的生态掌控力的,会投入大量的Tensorflow工程师针对自家TPU去做支持和优化,因此TPU去挑战英伟达GPU其实不存在所谓生态壁垒的问题。但是自谷歌自2016年推出第一代TPUv1至今已经到第四代TPUv4(2021年5月发布),仍然无法从英伟达手中抢走明显份额,其原因主要在于TPU本身性能相比于英伟达同时期GPU而言还有一定差距,另外其芯片设计过于专用所以在卷积之外的算法表现上并不算好:
(1)谷歌在芯片设计上的实力和英伟达相比还有一定差距
谷歌在TPU论文中也明确提到由于项目时间比较紧,所以很多优化只能放弃。从性能参数来看谷歌TPUv2和英伟达同年推出的V100相比,性能功耗比、显存带宽等指标有着明着差距,即使是谷歌在2018年推出了第三代TPU,其性能(FP32)、功耗等指标仍然和英伟达V100相比存在一定差距。
(2)谷歌采用的是传统脉动阵列机架构,芯片设计上过于专用
TPU的主要创新在于三点:大规模片上内存、脉动式内存访问、8位低精度运算。脉动阵列机做卷积时效果不错,但是做其他类型神经网络运算效果不是很好,在一定程度上牺牲了通用性来换取特定场景的高性能。TPU在芯片设计上只能完成“乘+加+乘+加......”规则的运算,无法高效实现“复数乘法、求倒、求平方根倒数”等常见算法。
现在AI芯片的行业趋势是:GPU在通用性的基础上逐渐增加专用计算单元;而类似TPU的ASIC芯片在专用性的基础上逐渐增加通用计算单元——两类芯片有逐渐收敛的趋势。英伟达在用于深度学习领域的GPU上的设计思路是“在通用的基础上增加专用运算单元”,例如在Volta架构上开始增加TensorCore(专门用于深度学习加速)、在Turing架构上开始增加RTCore(专门用于光线追踪加速),牺牲通用性为特殊的计算或者算法实现特殊架构的硬件以达到更快的速度。而AI芯片一开始走专用路线,但是现在在专用性之外也在架构设计上也增加了通用计算单元(例如谷歌TPUv1主要是矩阵乘法运算单元占了24%芯片面积,但是TPUv2也开始增加浮点ALU做SIMD)。
华为在2019年8月发布的昇腾910与英伟达在2020年5月发布的A100性能相当,但是我们认为华为的主要问题在于不具备深度学习框架生态掌控力。即使其芯片性能与英伟达水平差不多,但是由于Tensorflow/Pytorch两大主流深度学习训练框架没有基于华为昇腾910做特定的优化,所以算法结合上述两大训练框架在昇腾910上实际跑出来的性能其实不如英伟达A100;目前仅华为自研的深度学习框架MindSpore对昇腾910和昇腾310做了特别优化,由于华为MindSpore大部分精力都是放在对昇腾芯片的算子支持和优化上,对英伟达GPU的支持还不够,所以只有同时使用华为的深度学习框架和昇腾芯片才能同时发挥出两者的最佳性能。
上述我们提到要想在深度学习训练框架要想打破Tensorflow和Pytorch的垄断必须要靠原始创新,而目前包括华为MindSpore在内的国产深度学习框架尚未很好解决上述两大训练框架的痛点。Caffe之所以能够在早期获得开发者欢迎是因为解决了深度学习框架从0到1的过程,Tensorflow之所以可以取代Caffe是因为解决了其不够灵活、不能自动求导、对非计算机视觉任务支持不好等问题,Pytorch之所以明显抢夺Tensorflow的份额是因为Pytorch引入了动态图解决了Tensorflow是静态图设计调试困难的问题。但是目前国产的三个深度学习框架百度PaddlePaddle、旷视Megengine、华为MindSpore还没有完美解决开发者在用Tensorflow和Pytorch所遇到的痛点。
我们认为Tensorflow和Pytorch目前共同的痛点在于对海量算子和各种AI芯片支持的难度,华为正在探索靠AI编译器的技术来解决上述问题,但是目前编译技术仍然还达不到人工优化的效果。华为全面布局了三个层次的AI编译器,包括图灵完备的图层IR设计、使用poly技术的图算融合/算子自动生成技术(以TVM编译器的设计思想推出算子开发工具TBE来解决算子开发自动优化的问题)。
六
AI芯片市场预期
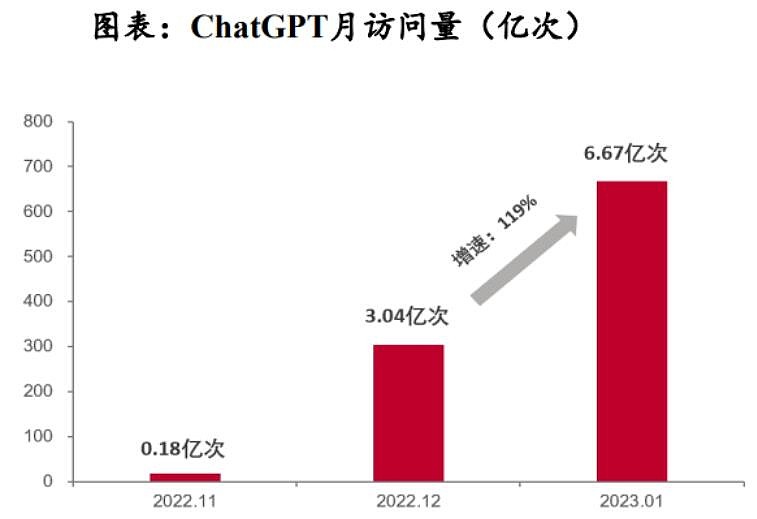
1.ChatGPT快速渗透,AI产业迎发展新机
ChatGPT是由OpenAI公司开发的人工智能聊天机器人程序,于2022年11月发布,推出不久便在全球范围内爆火。从用户体验来看,ChatGPT不仅能实现流畅的文字聊天,还可以胜任翻译、作诗、写新闻、做报表、编代码等相对复杂的语言工作。ChatGPT爆火的背后是人工智能算法的迭代升级。

ChatGPT是生成式人工智能技术(AIGC)的一种,与传统的决策/分析式AI相比,生成式AI并非通过简单分析已有数据来进行分析与决策,而是在学习归纳已有数据后进行演技创造,基于历史进行模仿式、缝合式创作,生成全新的内容。
ChatGPT单次训练所需算力约27.5PFlop/s-day,单颗NVIDIAV100需计算220天。随着模型参数的不断增加,模型训练所需算力将进一步提升,将进一步拉动对算力芯片的需求。预测随着ChatGPT等新兴AI应用的落地,将会不断打开下游市场需求,而伴随算力的增长,也将带来对上游半导体芯片的需求量快速提升。
2.全球AI芯片有望达到726亿美元规模
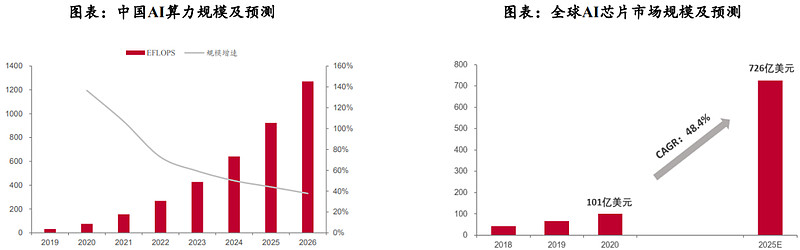
随着AI应用的普及和算力需求的不断扩大,AI芯片需求有望率先扩张。根据IDC预测,中国AI算力规模将保持高速增长,预计到2026年将达1271.4EFLOPS,CAGRA(2022-2026年)达52.3%。在此背景下,IDC预测异构计算将成为主流趋势,未来18个月全球人工智能服务器GPU、ASIC和FPGA的搭载率均会上升,2025年人工智能芯片市场规模将达726亿美元。
3.预测“文心一言”等LLM模型的推出将给国内GPU市场带来28.51亿美元的增量
据百度官方数据,“文心一言”基于文心大模型,参数规模为100亿,目前已经向公众开放,并将与搜索引擎业务整合。假设短期国内将出现5家与百度“文心一言”相似的企业,模型参数量与训练算力需求成比例。根据OpenAI公布的GPT3系列参数量及训练算力需求数据,可推算出文心大模型的单次训练算力需求为208.48PFlop/s-day。据Similarweb数据,2023年1月百度搜索引擎的访问量为4.9亿次,假设“文心一言”将整合到百度搜索引擎中,单日运营算力需求为125.08PFlop/sday。
根据NVIDIA数据,A100的FP64TensorCore算力为19.5TFlops,单价为1万美元。根据经验假设日常算力利用率为30%,则短期LLM模型将给国内GPU市场带来28.51亿美元的增量。长期LLM模型有望与搜索引擎结合,为GPU带来447.51亿美元的增量空间。假设未来ChatGPT将与搜索引擎结合,日活跃用户数量参考Google。根据Similarweb数据,2023年1月Google访问量为883亿。假设其他数据与测算方式不变,则ChatGPT与搜索引擎结合能够给GPU市场带来447.51亿美元的增量空间。

七
相关公司

1.龙芯中科
公司主要从事处理器(CPU)及配套芯片的研制、销售及服务。主要产品包括龙芯1号、龙芯2号、龙芯3号三大系列处理器芯片及桥片等配套芯片,系列产品在电子政务、能源、交通、金融、电信、教育等行业领域已获得广泛运用。
坚持自主研发指令系统、IP核等核心技术。龙芯中科掌握指令系统、处理器核微结构、GPU以及各种接口IP等芯片核心技术,在关键技术上进行自主研发,拥有大量的自主知识产权,已取得专利400余项。
GPU产品进展顺利,正研制新一代图形及计算加速GPGPU核。公司在2022年上半年完成了第一代龙芯图形处理器架构LG100系列,目前正在启动第二代龙芯图形处理器架构LG200系列图形处理器核的研制。根据公司在2022年半年度业绩交流会信息,第一代GPU核(LG100)已经集成在7A2000中,新一代GPGPU核(LG200)的研制也取得了积极进展。
2.海光信息
公司主营产品包括海光通用处理器(CPU)和海光协处理器(DCU)。海光CPU主要面向复杂逻辑计算、多任务调度等通用处理器应用场景需求,兼容国际主流x86处理器架构和技术路线。从应用场景看,海光CPU分为7000、5000、3000三个系列,分别定位于高端服务器、中低端服务器和边缘计算服务器。海光DCU是公司基于GPGPU架构设计的一款协处理器,目前以8000系列为主,面向服务器集群或数据中心。海光DCU全面兼容ROCmGPU计算生态,能够较好地适配国际主流商业计算软件,解决了产品推广过程中的软件生态兼容性问题。
CPU与DPU持续迭代,性能比肩国际主流厂商。CPU方面,目前海光一号和海光二号已经实现量产,海光三号已经正式发布,海光四号目前进入研发阶段。海光CPU的性能在国内处于领先地位,但与国际厂商在高端产品性能上有所差距,接近Intel中端产品水平;DCU方面,深算一号已实现商业化应用,深算二号已于2020年1月启动研发。在典型应用场景下,公司深算一号指标达到国际上同类型高端产品的水平。
3.景嘉微
公司主要从事高可靠电子产品的研发、生产和销售,产品主要涉及图形显控领域、小型专用化雷达领域、芯片领域等。图形显控是公司现有核心业务,也是传统优势业务,小型专用化雷达和芯片是公司未来大力发展的业务方向。
GPU研发进程平稳推进,新产品可满足AI计算需求。公司以JM5400研发成功为起点,不断研发更为先进且适用更为广泛的GPU芯片。2014年公司推出JM5400,核心频率550MHz;2018年推出JM7200系列,核心频率1300MHz;2021年推出JM9系列,核心频率1.5GHz。根据公司2022年中期报告,公司JM9系列第二款图形处理芯片于2022年5月成功研发,可以满足地理信息系统、媒体处理、CAD辅助设计、游戏、虚拟化等高性能显示需求和人工智能计算需求,可广泛应用于用于台式机、笔记本、一体机、服务器、工控机、自助终端等设备。
4.国民技术
国民技术股份有限公司是国内专业从事超大规模信息安全芯片和通讯芯片产品设计以及整体解决方案研发和销售的国家级高新技术企业。公司主要产品包括安全芯片和通讯芯片,其中,安全芯片包括USBKEY安全芯片、安全存储芯片、可信计算芯片和移动支付芯片。司作为我国最早的商用密码核心定点单位,以具有特定优势的安全密码算法性能、低功耗及无线连接传输技术为核心,利用公司长期积累的技术优势,不断提升产品的安全性与产品性价比,提高产品市场竞争力;同时,通过拓展多元化应用场景市场空间,降低对已有市场需求的业务依赖性,弥补市场变化因素带来的不利影响,保持安全芯片在行业市场中的较高市占率。
5.晶方科技
晶方半导体科技股份有限公司主营业务是传感器领域的封装测试业务。主要产品为芯片封装、芯片测试、芯片设计等。公司是中国大陆首家、全球第二大能为影像传感芯片提供WLCSP量产服务的专业封测服务商。公司获得国家集成电路产业投资基金股份有限公司投资,持股比例占总股本比例为5.98%,3月13日互动回复:公司"集成电路12英寸 TSV 及异质集成智能传感器模块项目进展顺利。
6.寒武纪
寒武纪是AI芯片领域的独角兽。公司成立于2016年3月15日,专注于人工智能芯片产品的研发与技术创新,产品广泛应用于消费电子、数据中心、云计算等诸多场景。公司是AI芯片领域的独角兽:采用公司终端智能处理器IP的终端设备已出货过亿台;云端智能芯片及加速卡也已应用到国内主流服务器厂商的产品中,并已实现量产出货;边缘智能芯片及加速卡的发布标志着公司已形成全面覆盖云端、边缘端和终端场景的系列化智能芯片产品布局。
人工智能的各类应用场景,从云端溢出到边缘端,或下沉到终端,都离不开智能芯片的高效支撑。公司面向云端、边缘端、终端推出了三个系列不同品类的通用型智能芯片与处理器产品,分别为终端智能处理器IP、云端智能芯片及加速卡、边缘智能芯片及加速卡。
八
AI芯片发展趋势
当前AI芯片呈现几大趋势:
1.制程越来越先进
从2017年英伟达发布TeslaV100AI芯片的12nm制程开始,业界一直在推进先进制程在AI芯片上的应用。英伟达、英特尔、AMD一路将AI芯片制程从16nm推进至4/5nm。
2.Chiplet封装初露头角
2022年英伟达发布H100AI芯片,其芯片主体为单芯片架构,但其GPU与HBM3存储芯片的连接,采用Chiplet封装。在此之前,英伟达凭借NVlink-C2C实现内部芯片之间的高速连接,且Nvlink芯片的连接标准可与Chiplet业界的统一标准Ucle共通。而AMD2023年发布的InstinctMI300是业界首次在AI芯片上采用更底层的Chiplet架构,实现CPU和GPU这类核心之间的连接。
3.头部厂商加速在AI芯片的布局
AI芯片先行者是英伟达,其在2017年即发布TeslaV100芯片,此后2020以来英特尔、AMD纷纷跟进发布AI芯片,并在2022、2023年接连发布新款AI芯片,发布节奏明显加快。
芯片成本变化有以下规律:封装形式越复杂,封装成本、封装缺陷成本占芯片成本比重越大:具体来说,SoC<MCM<InFO小于2.5D。芯片面积越大,芯片缺陷成本、封装缺陷成本占比越大;制程越先进,芯片缺陷成本占比越高,而Chiplet封装能有效降低芯片缺陷率,最终达到总成本低于SoC成本的效果。
制程越先进、芯片组面积越大、小芯片(Chips)数量越多,Chiplet封装较SoC单芯片封装,成本上越有优势。鉴于当前AI芯片朝高算力、高集成方向演进,制程越来越先进,Chiplet在更先进制程、更复杂集成中降本优势愈发明显,未来有望成为AI芯片封装的主要形式。
国产封测龙头,在Chiplet领域已实现技术布局:
通富微电已为AMD大规模量产Chiplet产品;长电科技早在2018年即布局Chiplet相关技术,如今已实现量产,2022年公司加入Chiplet国际标准联盟Ucle,为公司未来承接海外Chiplet奠定了资质基础;华天科技Chiplet技术已实现量产,其他中小封测厂商已有在TSV等Chiplet前期技术上的积累。















